SVD 文本图像转视频动画本地部署,Stable Video Diffusion AI视频开源发布,ComfyUI工作流|AI视频(图文版)
AI视频创作的热潮是从图生视频开始的,输入一张静态的图片,AI就能让它动起来,生成最长可达十几秒的一段动态视频。光影,自然细致,细节,栩栩如生,运动也十分流畅,堪比某些付费视频素材网站上出售的高质量空镜,内容还可以天马行空,不管是现实存在的还是不存在的。一下字把做了多年特效的UP主给干沉默了。这种几乎可以重塑剪辑后期产业的进展,让大众将关注集中在了一系列图生视频的AI工具上,例如最早出圈的Runway Gen-2,华人学霸打造的Pika等等。
这些强大的工具很受欢迎,唯一的缺点可能就是,要花钱还很贵,一个月几百的订阅费用你下得去手吗?但就在去年年底,Stable Diffusion的开发公司,开源模型界的抗击手Stability AI发布了他们的视频模型Stable Video Diffusion,简称SVD,成功依靠其免费,可本地运行的特性与不输主流产品的质量,在AI视频领域占据了一席之地。
它可以帮助你从一张静态图片,乃至一段提示词就去生成一系列丝滑、流畅且富有风格特色的视频分镜,你可以用它做动画,做视频素材,甚至是富有剧情的连续短片,连央视的宣传片里都有它的身影出现,你想知道它要怎么用吗?在今天这期视频里,我们来聊聊它的安装方法和运用心得,以及借助各种工具实现视频的运动设计、智能抠像,以及补帧放大等功能的方式。
下图是官方在线使用,免费额度有限,可以自己摸索。
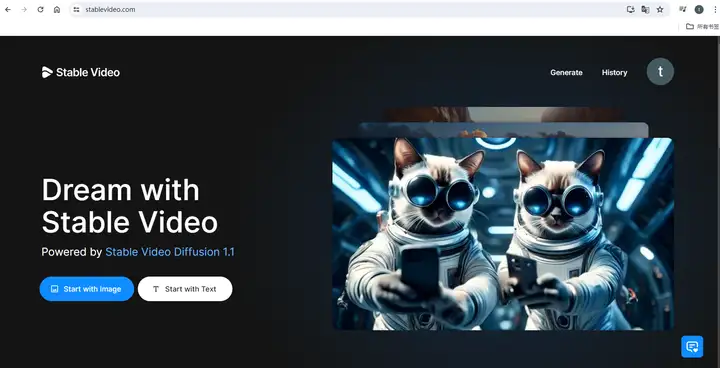
今天主要说本地部署,从它的下载与安装开始讲起吧.
下载地址:
2: 仅模型下载
3:教程工作流下载
6:SD1.5下载
你可以在Stability AI官方的Hugging Face模型页面,下载到最新版的SVD模型,最早发布的由两个版本,他们的区别是用于训练的视频帧数,不带XT的原版是在14帧视频上训练的,而加了XT的版本有额外在25帧的视频上进行过微调,理论上运动会更加流畅自然。我会推荐你下载最新版本1.1版本XT模型,以后也完全有可能有更新版本模型释出,优先用最新版。
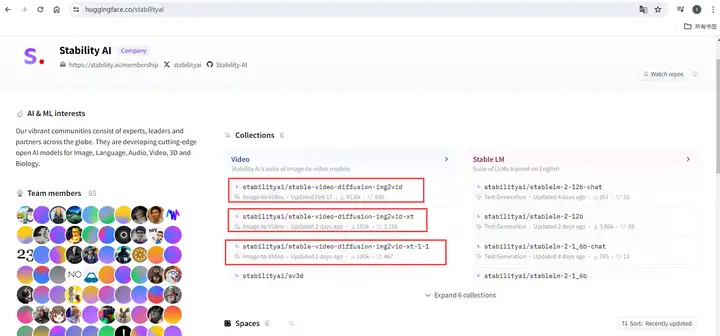
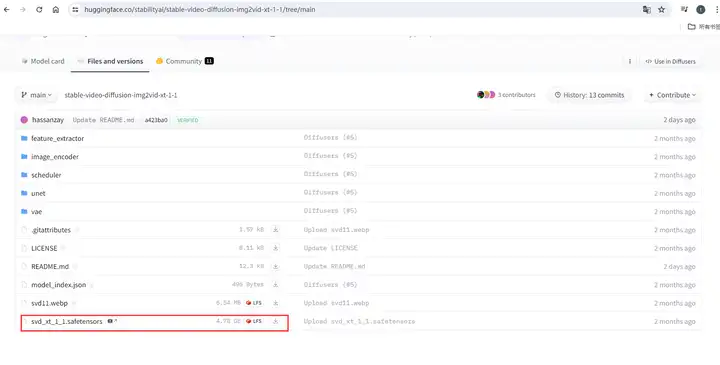
下载了模型以后,将下载的模型文件放入 ComfyUI 的 checkpoints 文件夹。
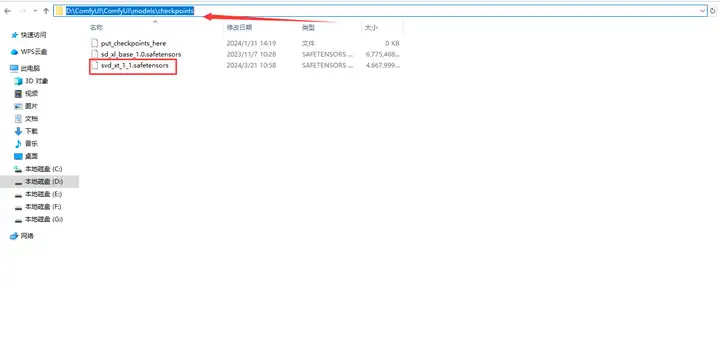
接下来,我们就从最基础的图生视频功能开始,了解如何实现一个化静为动的操作。
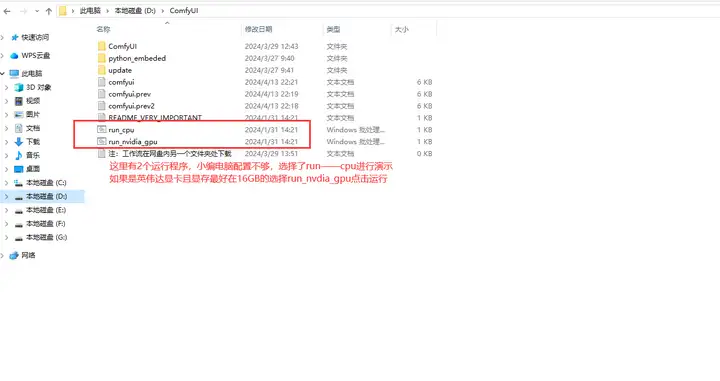
打开ComfyUI文件夹,找到run文件,双击运行
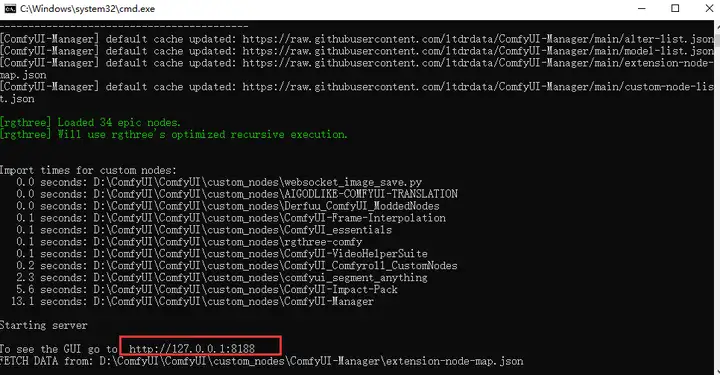
稍等一会加载完成,在本地浏览器打开这个地址127.0.0.1:8188
如下图:
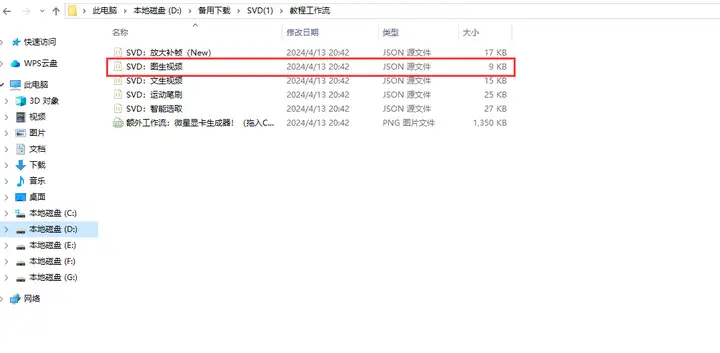
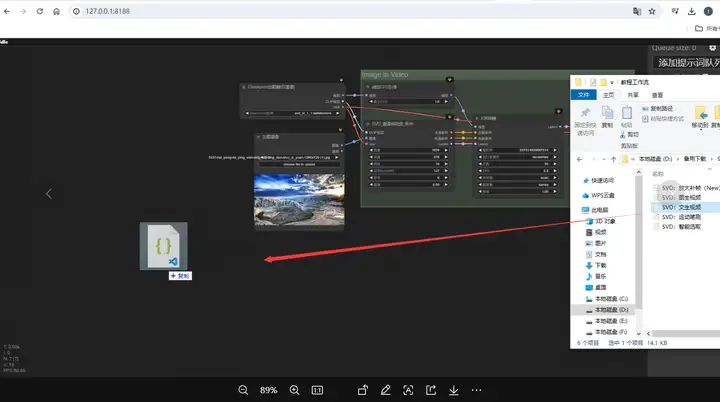
找到教程工作流里的SVD文生视频文件:
如下图拖动:
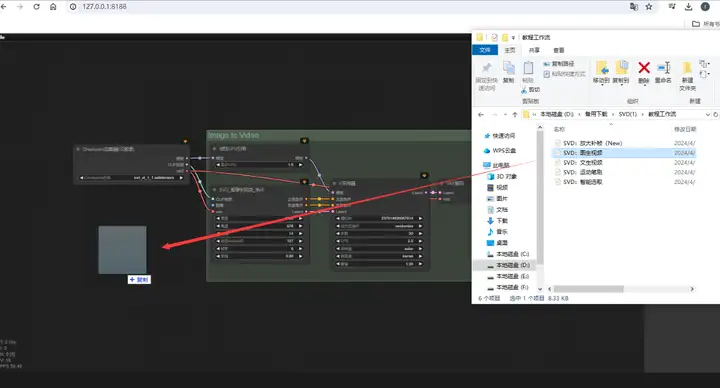
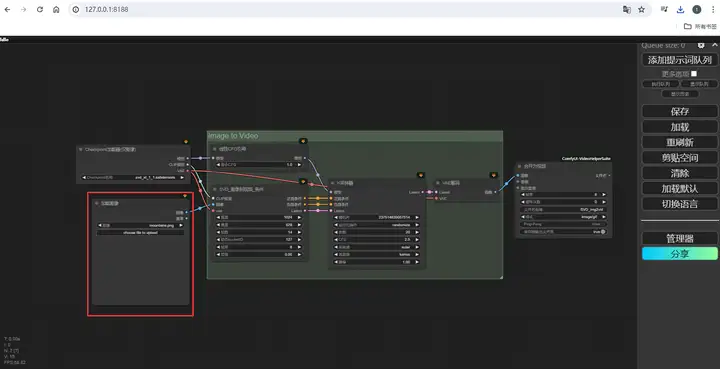
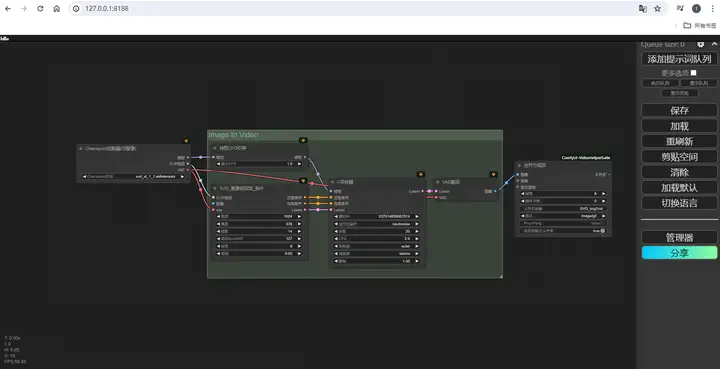
完成后应该是这样的画面。
在下方图片加载器处输入一张想要让它动起来的初始图片,可以直接从电脑上的文件夹里拖拽图片进来
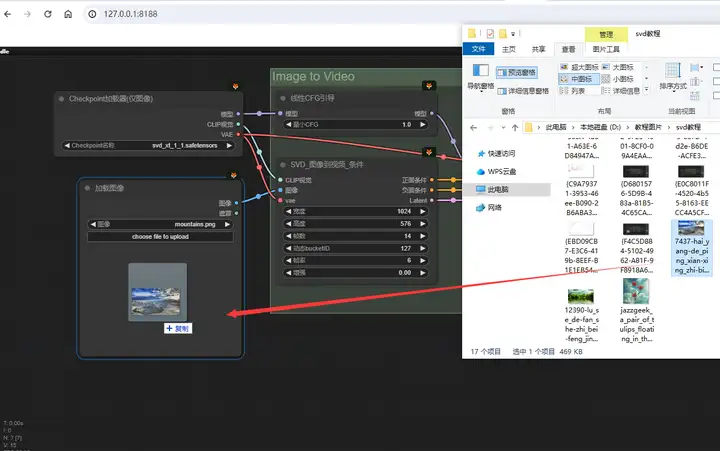
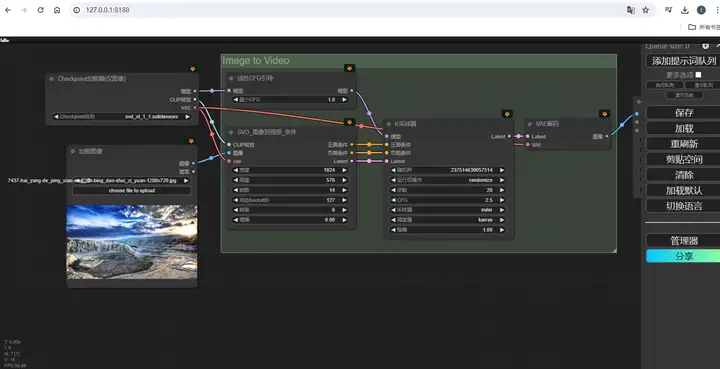
这张初始图片的尺寸最好和你最后生成的视频尺寸比例保持一致。那视频的尺寸在哪里调整呢?看到右边这个条件节点。在这里,你可以设置视频的宽度、高度和帧数、帧率的基本选项。其中视频尺寸我会推荐按照默认设置的1024 x 576来,因为SVD模型是在这个尺寸的视频上训练的,所以我们也应该尽可能把初始图像裁剪到16比9的比例上。视频的帧数决定了视频的总长度,同样会根据你选用的SVD模型而异,原版最佳选择是14帧,XT版本则是25帧。而FPS代表每秒播放的帧数,可以维持默认6不变。再在右边设置K采样器里的各项参数,这些参数和绘图时的作用基本一致,如果你不了解它们的详细作用也可以维持默认不变,
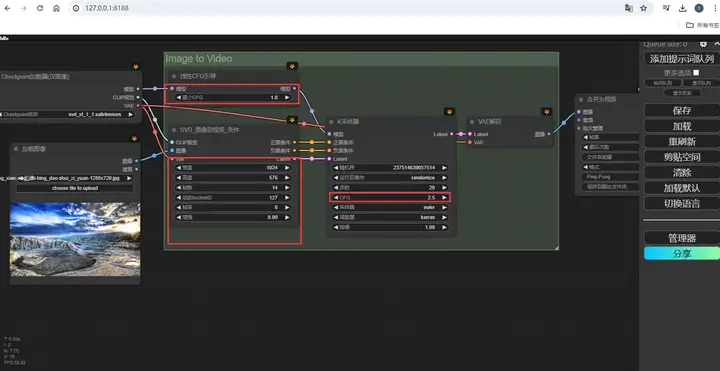
设置完毕,点击一下边栏上的”添加提示词队列”,等待读条完毕,在最右边的保存窗口里就会输出一段视频
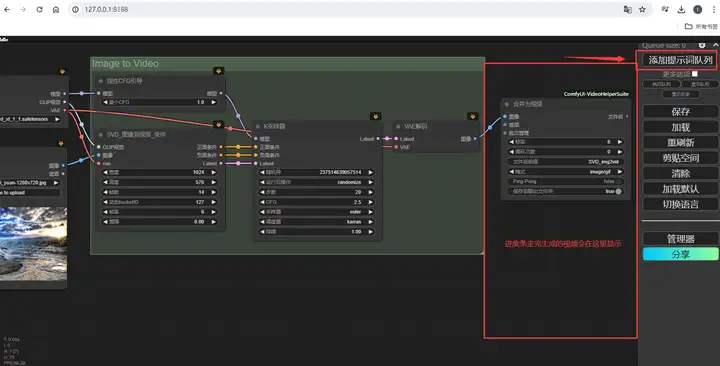
这样会生成一个约4秒左右的视频。你的图片就动起来了,你可以在ComfyUI根目录的输出文件夹里找到这些图片,也可以右键点击,将它保存下来。
不过,按照默认的这一套参数运行,有时生成的视频效果会有点奇怪,碰到类似这样的问题时,我们就得去更改下面这一系列和视频生成有关的参数了,这其中有三个,是需要你重点关注的。
首先是这个运动桶 ID(Motion Bucket ID):
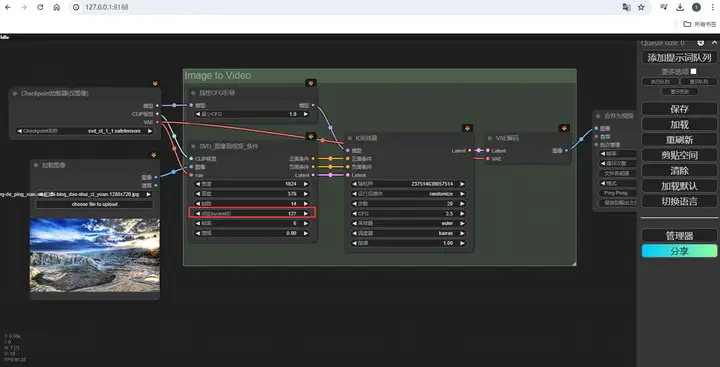
它是SVD模型里最直观的控制视频运动幅度的参数,默认127,范围从1到255,越大运动幅度就越剧烈,如果运动太剧烈导致画面变形了,就降低它。反过来,如果画面不怎么动,就可以适当增大它。
和运动相关另一参数是,是这两个节点里的最小CFG和KSampler里的CFG数值(Min CFG & KSampler CFG):
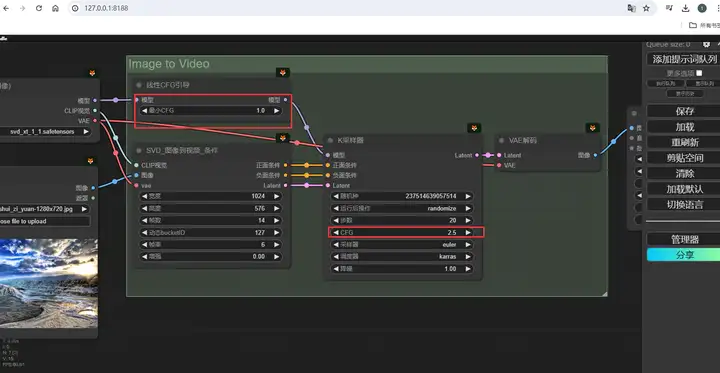
CFG是无分类器指导的缩写,和图像绘制中一样,它控制绘制内容与条件的相关性,你会看到有两个数值,是因为SVD采用了随帧数动态控制CFG的思路,在绘制第一帧内容时应用最小值,然后逐渐增大,到最后一帧时变成K-Sampler里的最终CFG,以此来适应视频不断变化的画面。官方解释它的作用是保持原始图像的最终程度,低了画面会更自由,而高了画面就会更稳定,我在实际摸索中发现它并不会影响大的运动构成,但会影响运动推导的细节。如果你的画面里出现了类似这样糊成一团的成分,就可以适当增大,另外,CFG太高或太低,也会导致画面的异常。如果碰到这种情况,就应当把它拉回到正常的区间内。
还有一个有用的参数是这个增强水平:
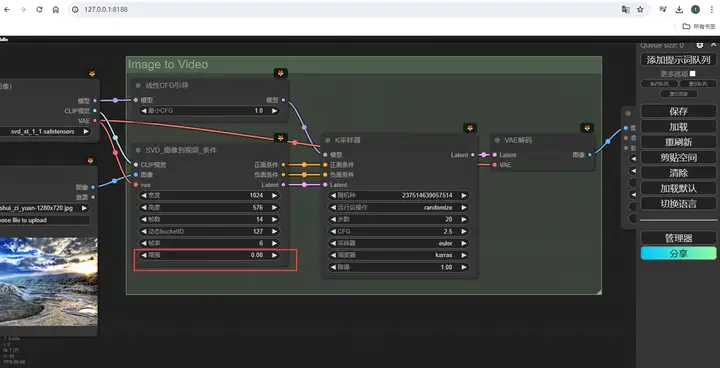
直接理解就是添加到图片中的噪声量,它越高,视频与初始帧的差异就越大,所以也可以通过增加它,来获得更多运动。但它的数值的调整很敏感,一般不超过1,不同场合使用的水平不同。多数时候,你可以让它保持默认,但当你使用与默认尺寸不同的视频尺寸时,最好把它增大到0.2到0.3,否则画面就有很大概率会是错乱的。
了解了这些,你就可以尽情享受SVD的便利了,有一张图片就能做出一段生动的视频素材来,不过,这里我们换想的用嘴拍视频好像还有一段距离,毕竟还得有图片,对吧?但其实,文生视频和图生视频本就只有一线之隔,而文生图的技术在过去一年多的锤炼里早就已经高度成熟了,因此,我们可以用一套非常流畅的文生图,图生视频的丝滑连招,实现从文字到视频的生成控制。在ComfyUI中加载这个工作流,比起刚刚的图生视频,它只是在前面多了一个文生图的节点组合。
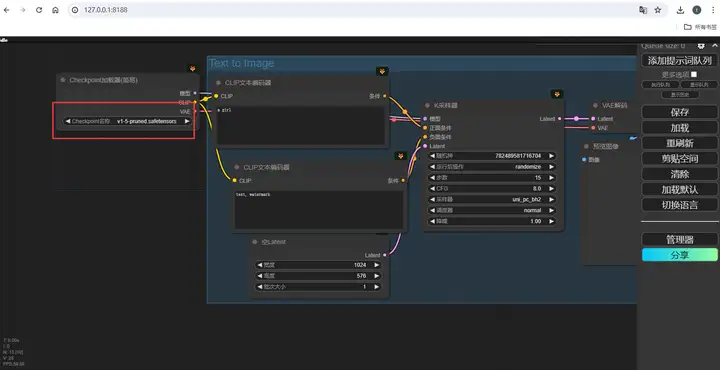
在最左边的模型加载器这里选择一个合适的绘图大模型,无论是SD1.5还是SDXL都可以。
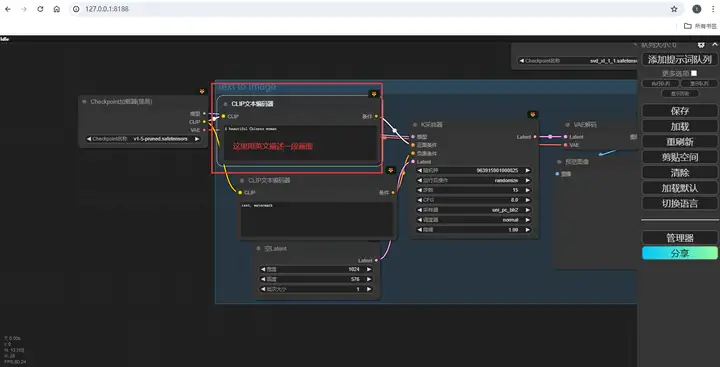
然后,在上方的文本编码器窗口里用英文输入一段画面的描述,按照刚刚提到的方法,再把视频相关的参数设置好,点击生成,它就会在第一个节点组里完成生成图片的工作,随后立刻将图片转化为一个动态视频。
(小编电脑配置不行,配置好的可以自行尝试。配置低了点击添加队列会结束进程)
其实,SVD用起来是非常自由的,原则上只要你能给它喂一张图片,它都能帮助你让图片动起来,因为AI视频模型的训练,就是向AI大量投喂视频片段,让它学习这些视频在不同时间节点上的静态帧的差异,久而久之,视频的所有动态,在他的眼里就会变得有迹可循,这个时候向AI输入一张静态的图片,它就会有能力去预测,接下来一段時間内它会发生画面运动,也因此,决定这个视频成色最重要的参数,其实就是这张图片。
如果你了解Stable Diffusion的应用教程,还可以利用多种手法绘制符合需求的图片,从而实现有指向性的视频创作。
如今已进入ai大模型时代,而要实现这一切,你需要强大的GPU支持。在这里小编推荐一下微星”魔龙”系列的4070 Ti SUPER,正是你开启AI视频创作之旅的完美伙伴。
16GB超大显存: 轻松驾驭SVD等AI视频模型,告别显存不足的烦恼,创作更流畅、更细致的动态画面。
接近RTX 4080的性能: 快速生成,大幅缩短渲染时间,让你的创意即刻呈现。
完美适配ComfyUI、Forge UI等AI创作工具: 掌控全局,轻松实现运动设计、智能抠图、补帧放大等功能,释放你的无限想象力。
支持Lora模型: 轻松将微星GeForce RTX 40系列显卡的酷炫形象植入你的作品,创作专属风格!





