在人工智能领域,代码的生成与审查一直是技术进步的关键战场。OpenAI最新推出的CriticGPT是一款基于GPT-4的模型,专门用于审查ChatGPT生成的代码并找出其中的错误。这一创新工具的问世,标志着人工智能在自我监督和错误检测方面实现了重要突破。
CriticGPT的诞生旨在弥补这一缺陷。它通过生成自然语言评论来协助人类专家更准确地评估代码,从而显著提高了错误检测的能力和效率。无论是语法错误、逻辑错误还是安全漏洞,CriticGPT在识别代码错误方面都表现出色,能够逐一识别并指出。
CriticGPT通过强化学习和人类反馈进行训练,专注处理包含错误的输入。研究人员通过在代码中人为插入错误并提供反馈来训练它。研究表明,CriticGPT检测到的错误数量甚至超过了人类评估者,这一发现对代码审查领域具有革命性意义。

在开发 CriticGPT 的过程中,模型接受了包含故意插入错误的输入训练。人类训练员修改 ChatGPT 编写的代码,故意引入错误,然后提供反馈,模拟发现错误的情景,帮助模型学会识别和指出各种编码错误。

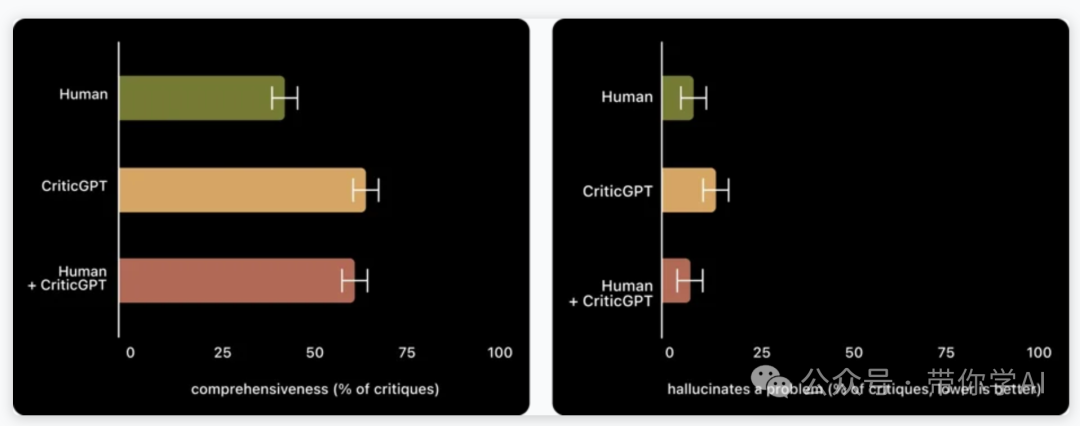
实验显示,CriticGPT 能捕捉 ChatGPT 输出中的插入错误和自然错误。在63%涉及自然错误的案例中,训练者更偏好 CriticGPT 的结果,而不是 ChatGPT 生成的结果。这是因为 CriticGPT 产生的无用“意见”更少,误报或幻觉问题也更少。
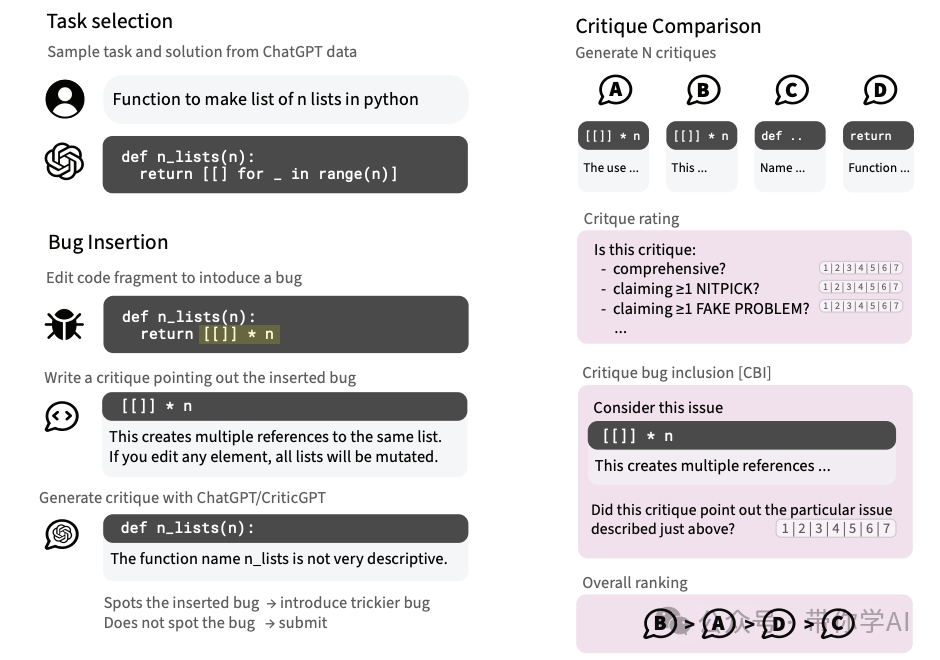
研究人员开发了“强制采样束搜索”(FSBS)技术,用于改进 CriticGPT 的代码评论能力。FSBS 能调整 CriticGPT 查找问题的彻底程度和减少虚假问题的出现,以适应不同的 AI 训练任务。
有趣的是,CriticGPT 不仅能审查代码。在一个人类评为完美的 ChatGPT 训练数据子集上测试时,CriticGPT 发现了 24% 的错误,并得到了人类审阅者的确认,显示出其在非代码任务中的潜力和捕捉细微错误的能力。
尽管 CriticGPT 取得了积极成果,但仍有局限。它在相对较短的 ChatGPT 答案上训练,可能无法评估更长、更复杂的任务。此外,虽然减少了虚假行为,但无法完全消除,人类训练师仍可能因为错误输出而犯错。
同时,OpenAI对 CriticGPT 的研究中,发现将 RLHF 应用于 GPT-4 有望帮助人类为 GPT-4 生成更好的 RLHF 数据,因此后续他们也准备进一步应用研究。





