AI挑战中国高考
包括OpenAI的ChatGPT-4o在内的七款顶尖语言模型接受了一项特别的挑战:参加了中国高考。这些模型在英语和语文科目中展现了不俗的实力,但数学科目却是它们的软肋,所有参试的模型都未能通过数学考试。
OpenCompass测试
这次测试由上海人工智能实验室的评估系统OpenCompass执行,涵盖了来自阿里巴巴集团、智谱AI、上海人工智能实验室以及法国Mistral AI等开发的开源模型。上海人工智能实验室认为,中国的大学入学考试以其严格的标准,是检验语言大模型(LLM)智能水平的绝佳方式。值得一提的是,这些考试全部由人工评分,而评卷老师并不知道答卷来自机器。考试内容不仅包括选择题,还有主观题。
据OpenCompass最新发布的成绩单显示,阿里巴巴的Qwen 2-72B以其卓越的表现领跑,三科总分420分中获得了303分。紧随其后的是OpenAI的Chat GPT-4o,以296分位列第二,而上海人工智能实验室的InternLM 2.0以295.5分紧随其后。而Mistral AI的模型在这场考试中表现最差,仅获得185分。
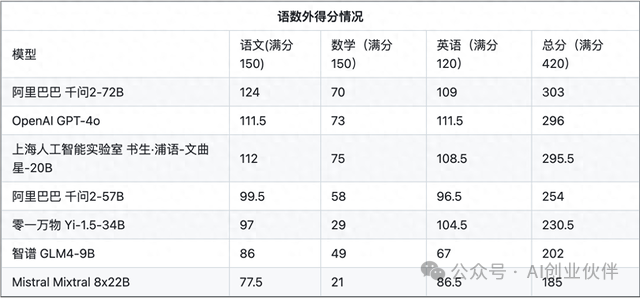

语言战场的胜利与数学的挫败
尽管在语文和英语科目中表现出色,但所有模型在数学科目中的挫败揭示了它们在处理复杂推理和解题过程中的不足。InternLM 2.0在数学科目中得分最高,但也仅有150分中的75分,而GPT-4o以73分位居第二。
评卷老师注意到,这些AI模型在解答数学主观题时表现出了逻辑混乱,有时虽然得出了正确答案,但其推理过程却是错误的。这揭示了虽然这些大型语言模型(LLM)能够有效记忆公式,但在阐述解题步骤时却显得力不从心。
AI的创作自由与人类的规则束缚
上海人工智能实验室的科学家林大华在接受媒体采访时指出,这一结果表明LLM在数学技能方面还有很大的进步空间。数学不仅仅是关于计算,更多的是涉及复杂的逻辑推理,这对于LLM在金融等关键领域的应用至关重要。
此外,这些AI模型在现代汉语方面的表现尚可,但对于古代汉语的掌握则有明显不足。在这方面,Qwen以124分的成绩领先,而GPT-4o则在英语测试中以109分的好成绩脱颖而出。
值得一提的是,在英语写作方面,人类考生常因内容不足而失分,而AI模型则因超出字数限制而被扣分,这一现象反映了AI在遵循指定要求方面的挑战。





