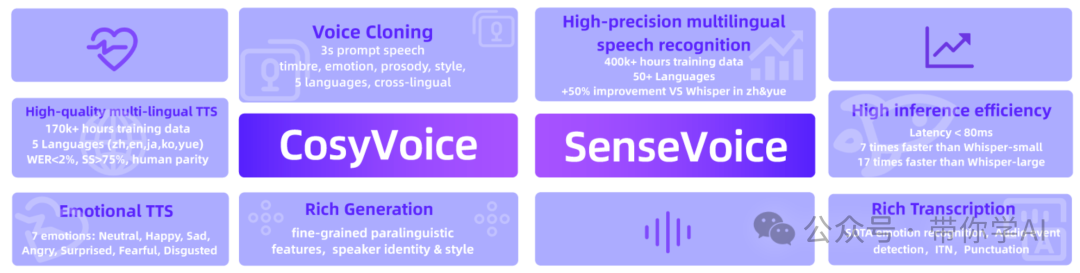
阿里通义实验室近期开源了一个名为FunAudioLLM的音频生成大模型项目,旨在增强人类与大型语言模型(LLMs)之间的自然语音交互体验。其核心是两个创新模型:
- CosyVoice专注于自然语音生成,支持中、英、日、粤、韩五种语言,具备音色和情感控制功能。它通过15万小时的数据训练,能够快速模拟音色,并提供细粒度的情感和韵律控制。
- SenseVoice专注于高精度的多语言语音识别、情感识别和音频事件检测。经过40万小时的数据训练,支持超过50种语言,识别效果优于Whisper模型,尤其在中文和粤语上提升超过50%。SenseVoice还具备情感识别和音频事件检测功能。
开源的模型和代码现已在ModelScope和Huggingface上发布,同时GitHub也提供了训练、推理和微调代码。CosyVoice和SenseVoice模型在ModelScope上有在线体验,方便用户直接尝试这些先进的语音技术。(体验链接在文章最后)
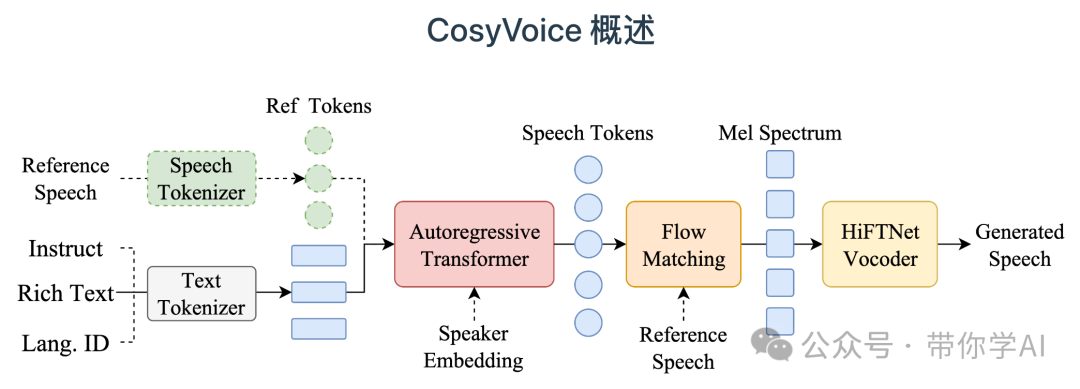
CosyVoice 由一个自回归变换器(用于为输入文本生成相应的语音标记)、一个基于 ODE 的扩散模型、流匹配(用于从生成的语音标记重建梅尔频谱)和一个基于 HiFTNet 的声码器(用于合成波形)组成。虚线模块在特定模型用途中是可选的,例如跨语言、SFT 推理等。
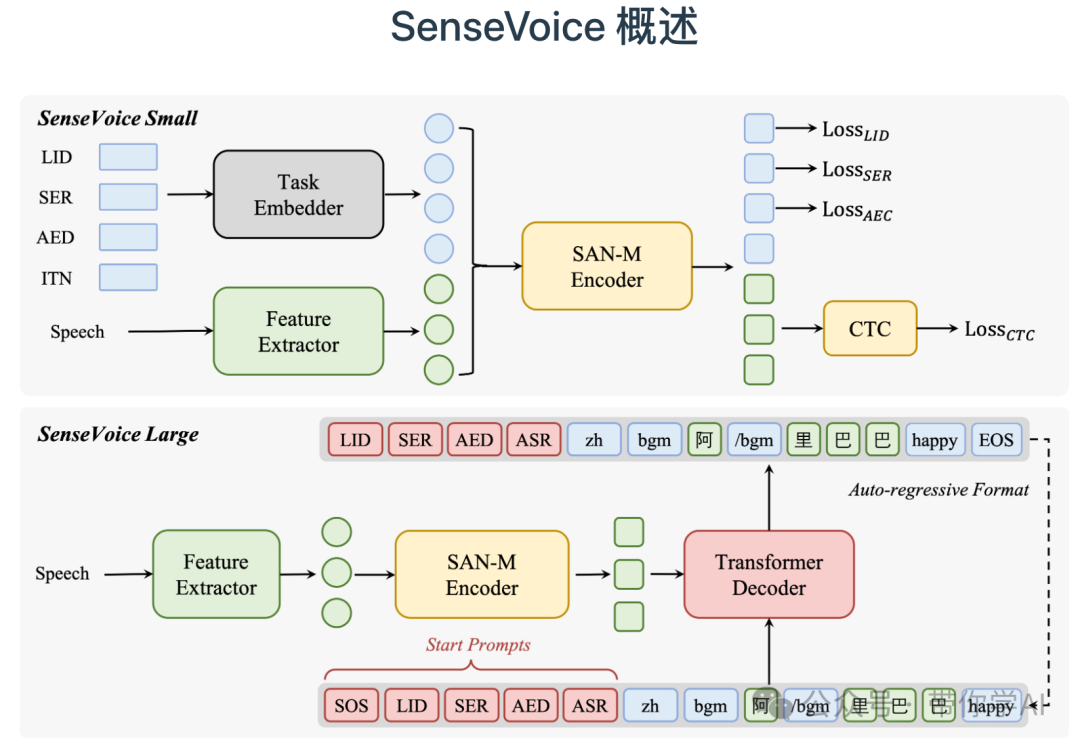
SenseVoice 是一个语音基础模型,具有多种语音理解功能,包括 ASR、LID、SER 和 AED。SenseVoice-Small 是一个仅编码器的语音基础模型,可实现快速语音理解;SenseVoice-Large 是一个编码器-解码器语音基础模型,可实现更准确的语音理解,并且支持更多语言。
基于SenseVoice和CosyVoice模型,FunAudioLLM可支持较多的人机交互应用场景,例如音色情感生成的多语言语音翻译、情绪语音对话、互动播客、有声读物等。
语音到语音翻译
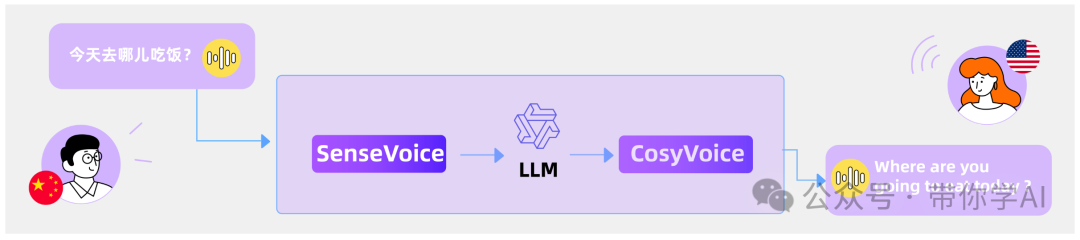
通过整合 SenseVoice、LLM 和 CosyVoice,我们可以轻松进行语音到语音翻译 (S2ST)。请注意,原始录音以粗体突出显示。(效果第一个视频)
情感语音聊天
通过整合SenseVoice、LLMs和CosyVoice,我们可以开发一个情感语音聊天应用程序。在下面的示例中,用户和助手的内容均由CosyVoice合成。

互动播客
通过整合 SenseVoice(一个基于 LLM 且具有实时世界知识的多智能体系统)和 CosyVoice,我们可以创建一个交互式播客。
富有表现力的有声读物
通过 LLM 的分析能力来构建和识别书中的情感,并将其与 CosyVoice 相结合,我们实现了表现力增强的有声读物。
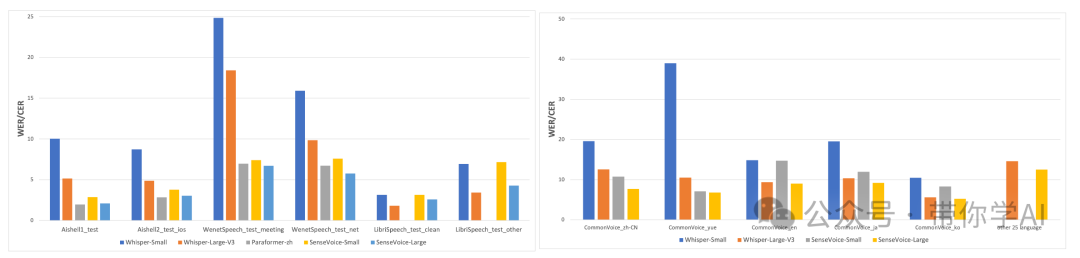
在开源基准数据集(包括 AISHELL-1、AISHELL-2、Wenetspeech、Librispeech 和 Common Voice)上对比了 SenseVoice 和 Whisper 的多语言识别性能和推理效率。推理效率评估使用 A800 机器进行。SenseVoice-small 采用非自回归端到端架构,推理延迟极低,比 Whisper-small 快 7 倍,比 Whisper-large 快 17 倍。
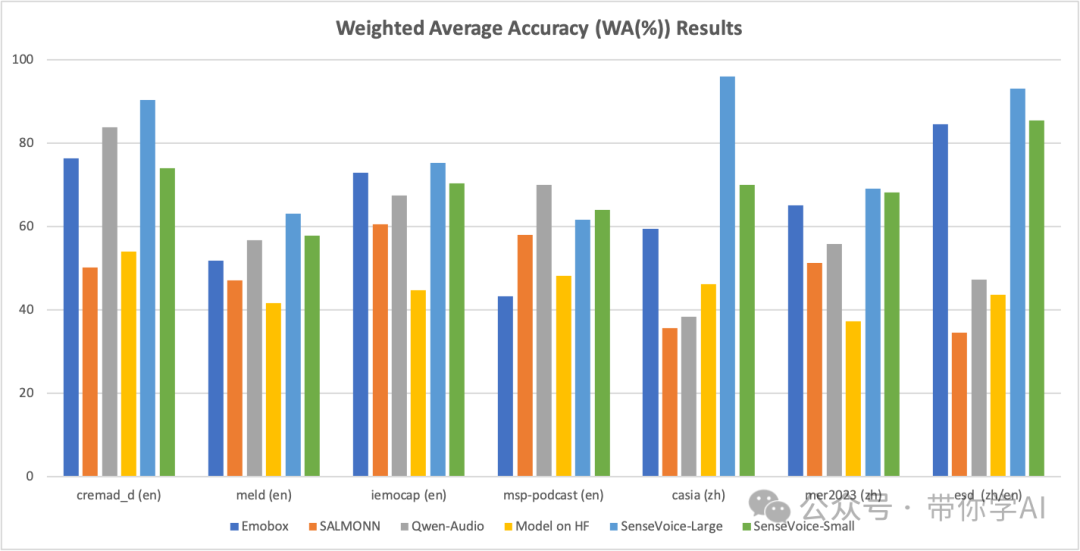
SenseVoice 还可用于离散情绪识别。支持快乐、悲伤、愤怒和中性。在 7 种流行的情绪识别数据集上对其进行了评估。即使没有对目标语料库进行微调,SenseVoice-Large 也可以在大多数数据集上接近或超过 SOTA 结果。
在线体验
SenseVoice:https://www.modelscope.cn/studios/iic/SenseVoice
CosyVoice:https://www.modelscope.cn/studios/iic/CosyVoice-300M








