AI应用进展和演化
1-1. 蚂蚁集团基于蚂蚁百灵大模型平台研发多模态遥感模型SkySense:多项测评中均名列第一
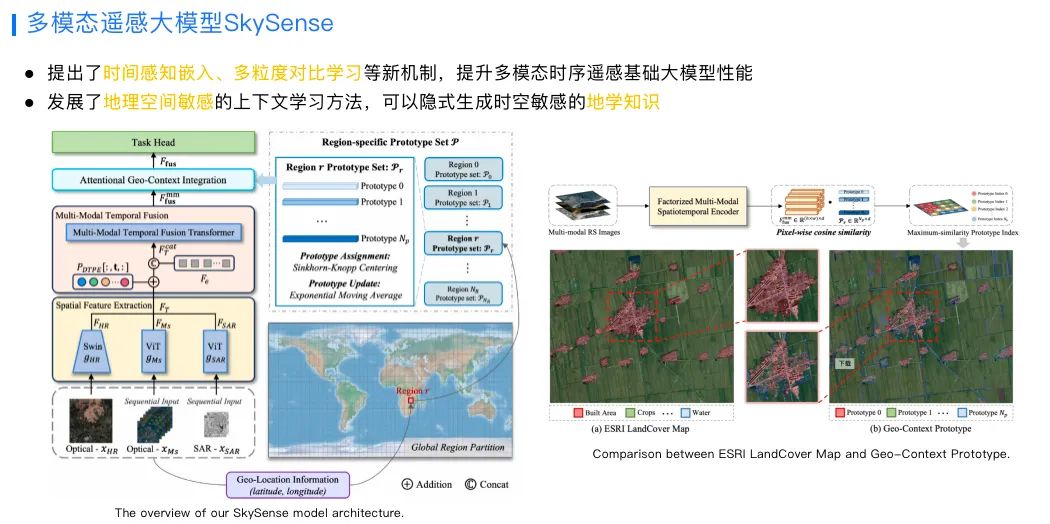
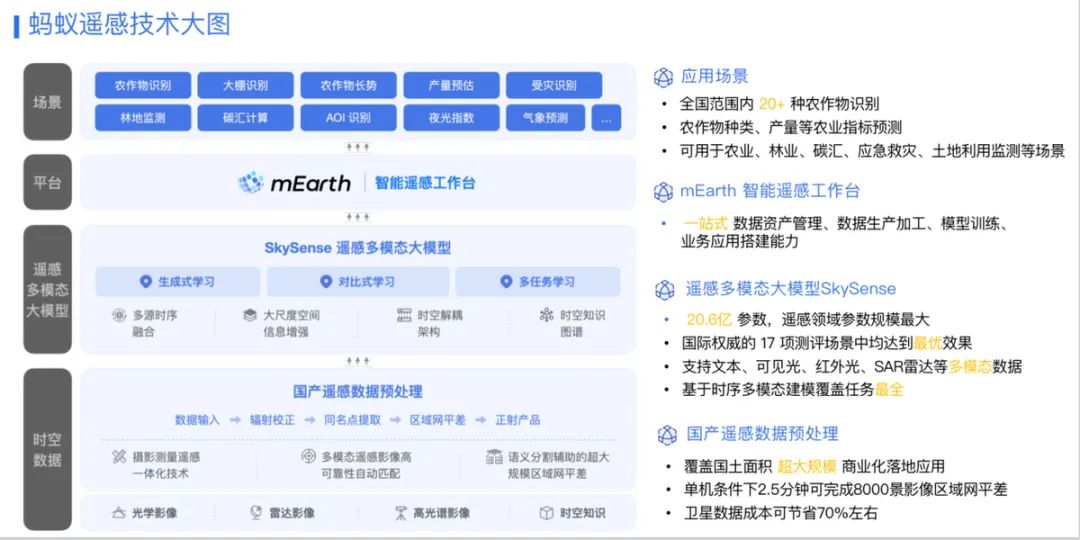
通过在数据、模型架构和无监督预训练算法等方面的技术创新,SkySense在土地利用监测、地物变化检测等7种常见遥感感知任务,17项测评中均名列第一。 训练这个模型,采集了分布于全球的2150万组样本,每一组样本都包含了高分光学、时序光学、雷达SAR影像。这些数据覆盖全球40多个国家和地区,覆盖土地达到878万平方公里,有300TB。
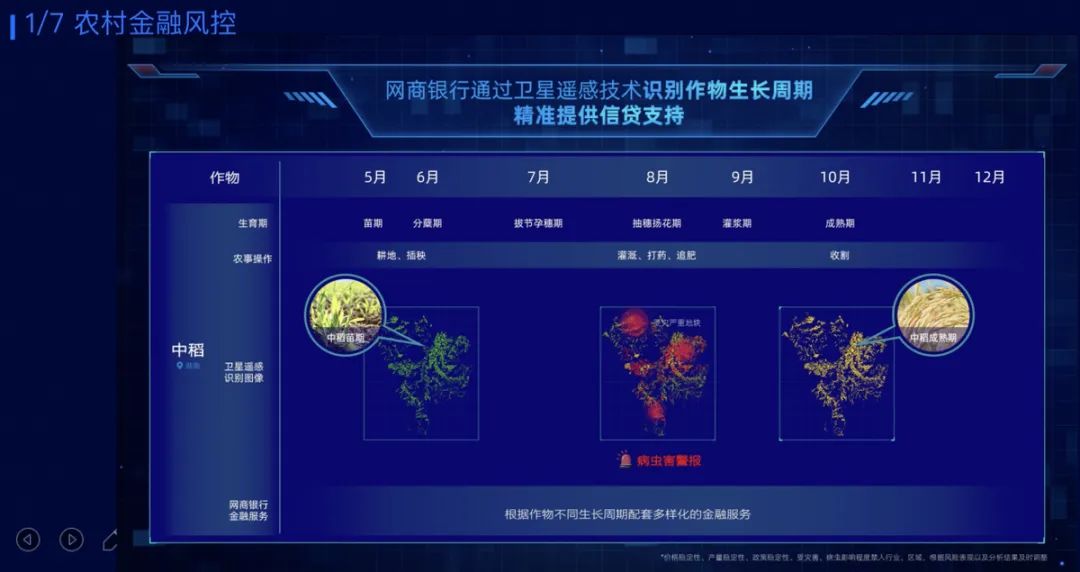
同时,SkySense在农村金融、蚂蚁森林林地保护等场景的应用。例如能够精准地识别不同时期农作物的种类,以及是否受到病虫害等信息,还能分析出这个农作物正处在什么生长周期,根据不同的生长周期匹配多样化的金融服务,从而为农民提供更好信贷的支持。
https://www.jiqizhixin.com/articles/2024-07-12

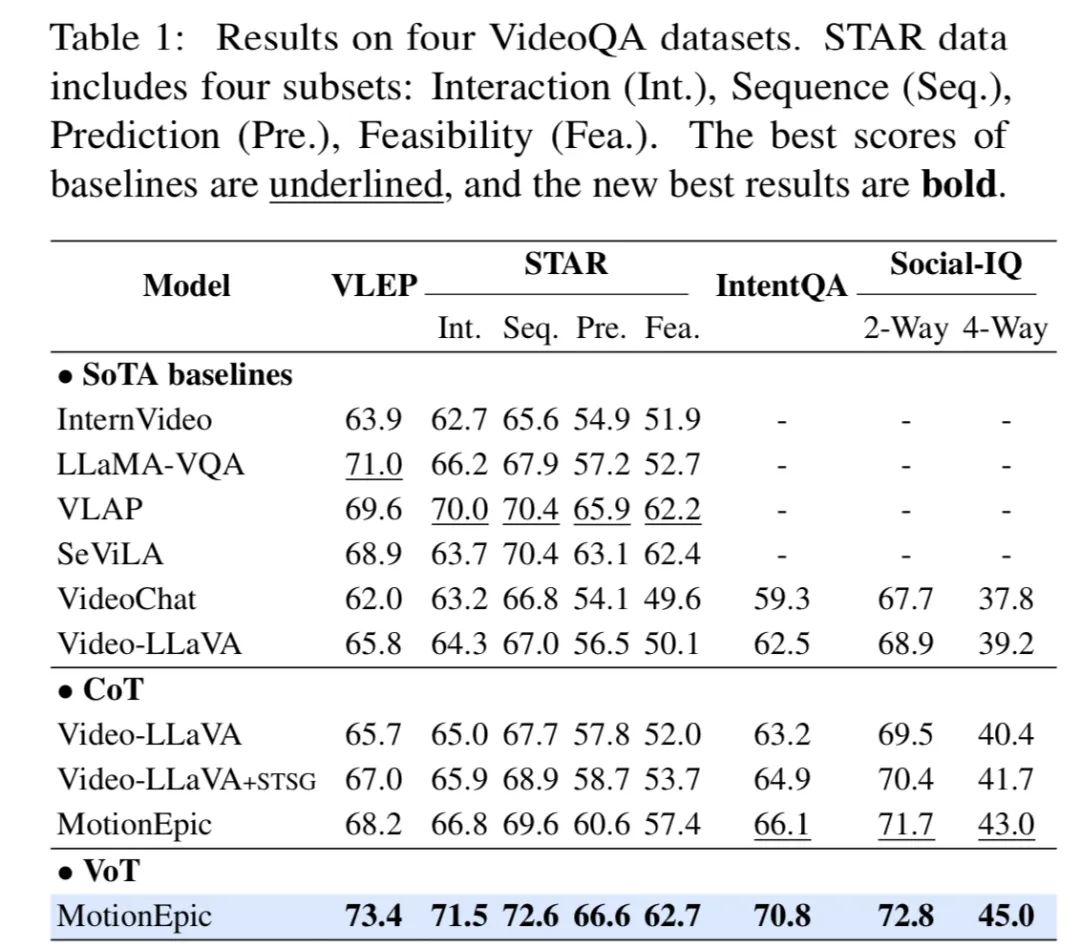
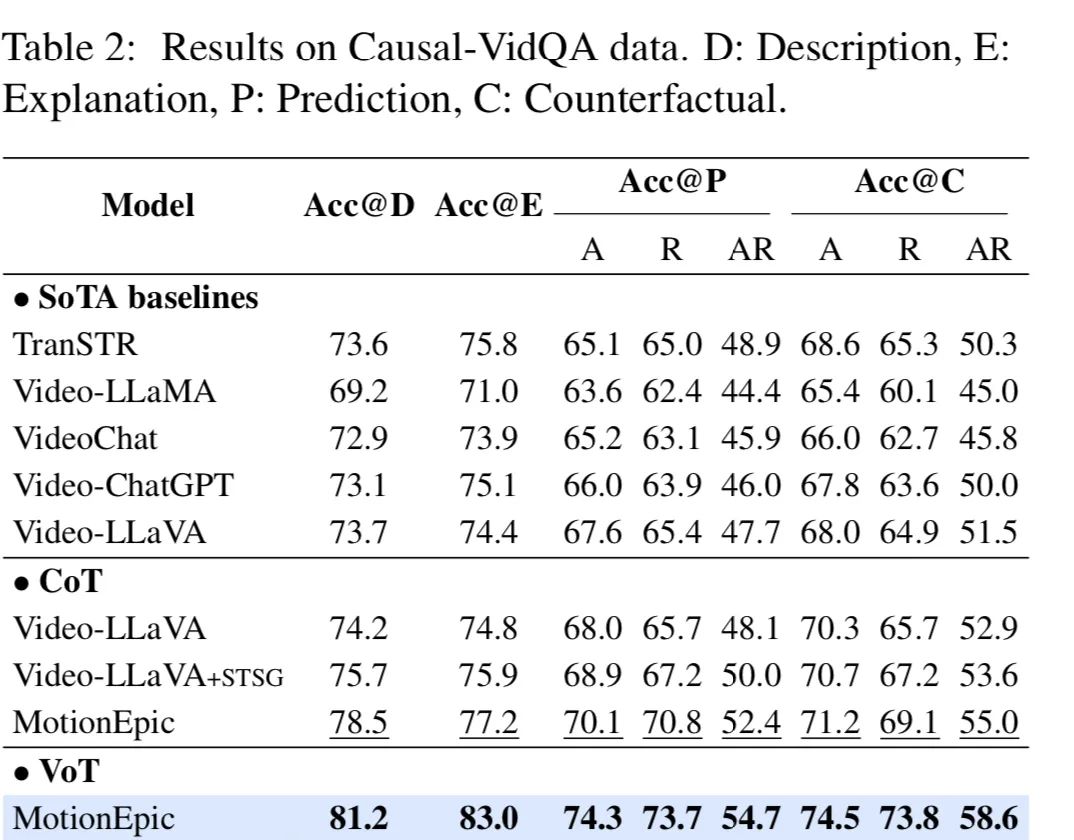
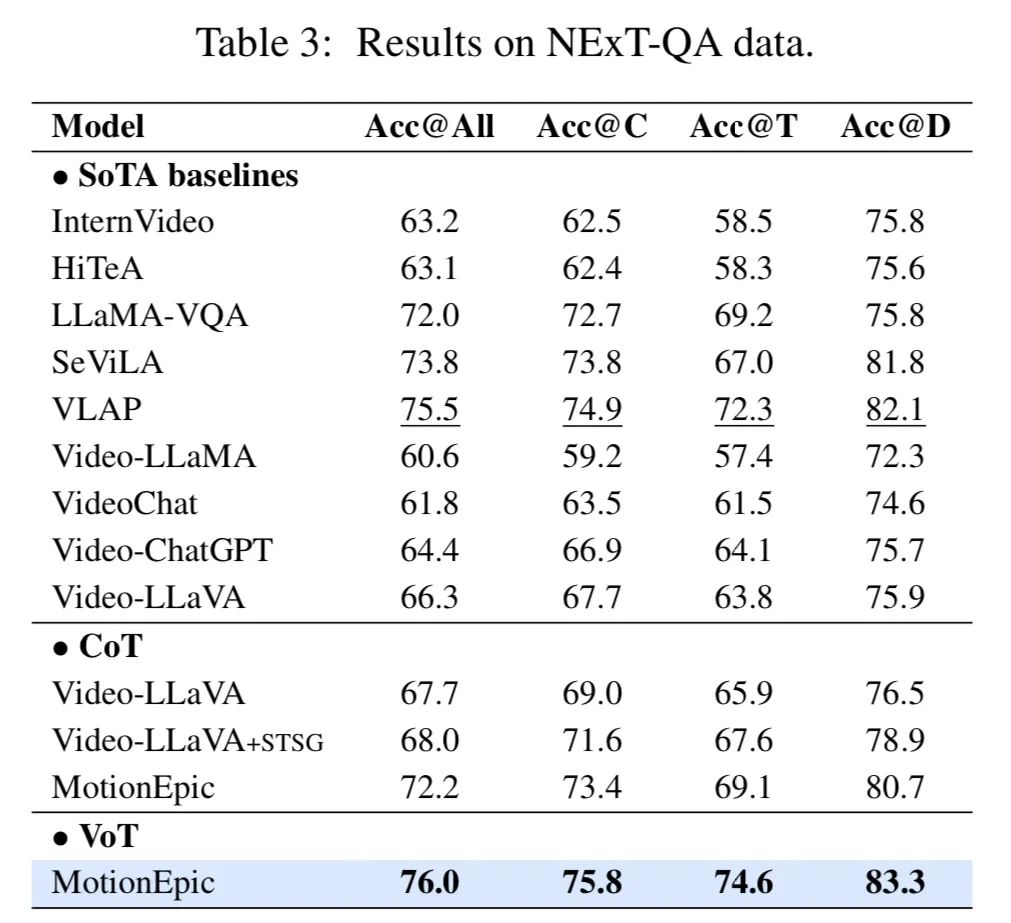
1-2. 首个视频思维链推理框架Video-of-Thought来了MotionEmpic:像人一样从感知到认知全面推理视频,显著提升模型效果
新加坡国立大学联合南洋理工大学和哈工深的研究人员共同提出了一个全新的视频推理框架,这也是首次大模型推理社区提出的面向视频的思维链框架(Video-of-Thought, VoT)。 视频思维链VoT让视频多模态大语言模型在复杂视频的理解和推理性能上大幅提升。该工作已被ICML 2024录用为Oral paper。
实验结果表明,作者提出的全新推理框架可显著提升模型在各类视频QA上的性能,超越了当前所有传统视频MLLM以及CoT方法的表现。
https://www.jiqizhixin.com/articles/2024-07-12-3

1-3. 机器人大模型新公司Skild AI :搭建通用机器人智能模块,数据规模比同行大1000倍
位于匹兹堡的机器人初创 Skild AI 声称,已经开发出一种通用的智能系统。 它就像一个通用的智能模块,可以接入不同机器人,让他们立刻获得一些基本能力,如爬坡、跨过障碍、识别和捡起物品。
模型泛化能力和涌现能力,离不开所谓「规模空前」的数据集:一个由文本、图像和视频组成的庞大数据集。官方说法,比竞争对手使用的数据库大 1000 倍。
7 月 9 日,Skild AI 正式宣布筹集到 3 亿美元 A 轮融资,公司估值达 15 亿美元。投资人阵容也非常强大,涵盖科技界、顶尖风投甚至学术机构。
https://www.jiqizhixin.com/articles/2024-07-12-9


他们的基础模型在比其竞争对手大 1000 倍的数据集上进行训练,可以接入各种机器人,帮助他们获得如爬坡、识别和捡起物品等基础能力
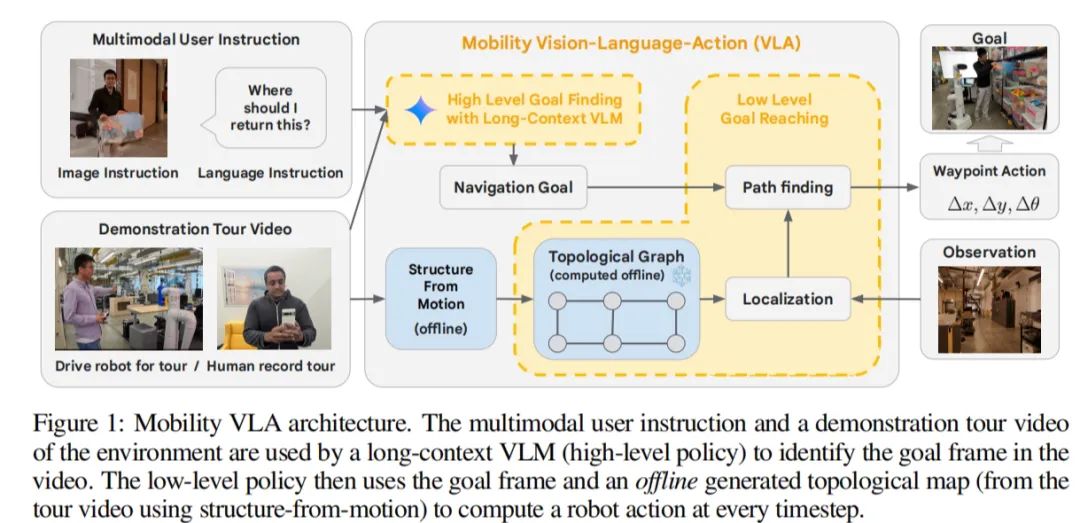
1-4. 谷歌最强Gemini 1.5 Pro加持,Mobility VLA:让机器人在836平方米的办公室里轻松导航,指令完成率达90%
拍摄指定区域(如家庭或办公空间)的视频导览,让Gemini 1.5 Pro加持的机器人「观看」视频以了解环境。 接下来,利用Mobility VLA将环境理解和常识推理能力结合起来。然后,机器人可以根据观察和学习到的情况,对书写和语音的指令以及手势做出反应。
例如,在用户展示一部手机并询问「在哪里可以充电」后,机器人会引导用户找到电源插座。DeepMind表示,在一定空间内,用Gemini驱动的机器人,在发出50多条用户指令后,完成指令成功率高达90%。
https://www.163.com/dy/article/J6T81DSI0511ABV6.html
首先,让RT-2带自己去一个能画东西的地方。戴着一个可爱的的黄色领结机器人回应道,「好的,给我一分钟,让我用Gemini稍加思考」。

不一会儿功夫,它就把人类带到一块墙壁大小的白板前。


论文名称:Mobility VLA: Multimodal Instruction Navigation with Long-Context VLMs and Topological Graphs
论文地址:https://arxiv.org/abs/2407.07775v1
1-5. 日本科学家开发AI只需X射线片即可判断肺功能
临床医生可以用x光片来判断一个人是否患有肺结核、肺癌或其他疾病,但他们不能用x光片来判断肺部功能是否正常。到目前为止,的确如此。 在发表在《柳叶刀数字健康》杂志上的研究结果中,大阪城市大学医学研究生院的副教授Daiju Ueda和Yukio Miki教授领导的一个研究小组开发了一种人工智能模型,可以从胸部x光片中准确估计肺功能。
上田教授和研究小组使用近20年的14万多张胸片对人工智能模型进行了训练、验证和测试。他们将实际的肺活量测量数据与人工智能模型的估计进行了比较,以微调其性能。结果显示出非常高的一致性,Pearson相关系数(r)大于0.90,表明该方法具有足够的实际应用前景。
https://m.ebiotrade.com/newsf/2024-7/20240709075852076.htm
AI大模型算法和峰会
2-1. 把AI的“慢思考”结果蒸馏进“快思考”:Llama2表现提升257%超GPT4,同时降低推理成本
对于大模型而言,模仿人类的“系统2”的方式有很多种,在模型中所处的环节也不尽相同,这里作者一共研究了四种:
1. CoT,即Chain of Thought,思维链,从提示词入手让模型逐步思考;
2. S2A,即System 2 Attention,由Meta自己提出,直接修改了模型的注意力机制,屏蔽与任务无关的信息;
3. RaR,即Rephase and Respond,先对问题进行重新表述,再根据重述后的问题生成答案;
4. BSM,即Branch-Solve-Merge,将复杂任务分解为多个分支,针对每个分支独立生成评分,再将各个分支的评分综合。https://www.qbitai.com/2024/07/165939.html
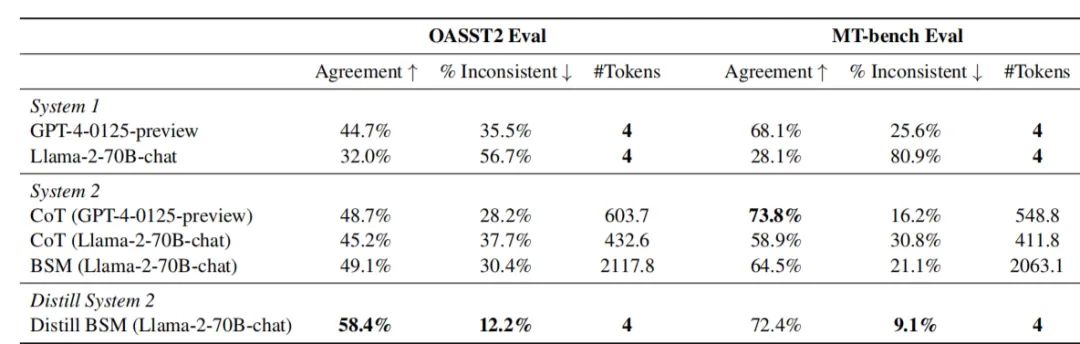
在两个数据集中,Llama-2的表现(人类一致性)分别从32.0%和28.1%,提高到了58.4%和72.4%,最高增幅达到了257%,比CoT方法更加有效。

论文名称:Distilling System 2 into System 1
论文地址:https://arxiv.org/abs/2407.06023
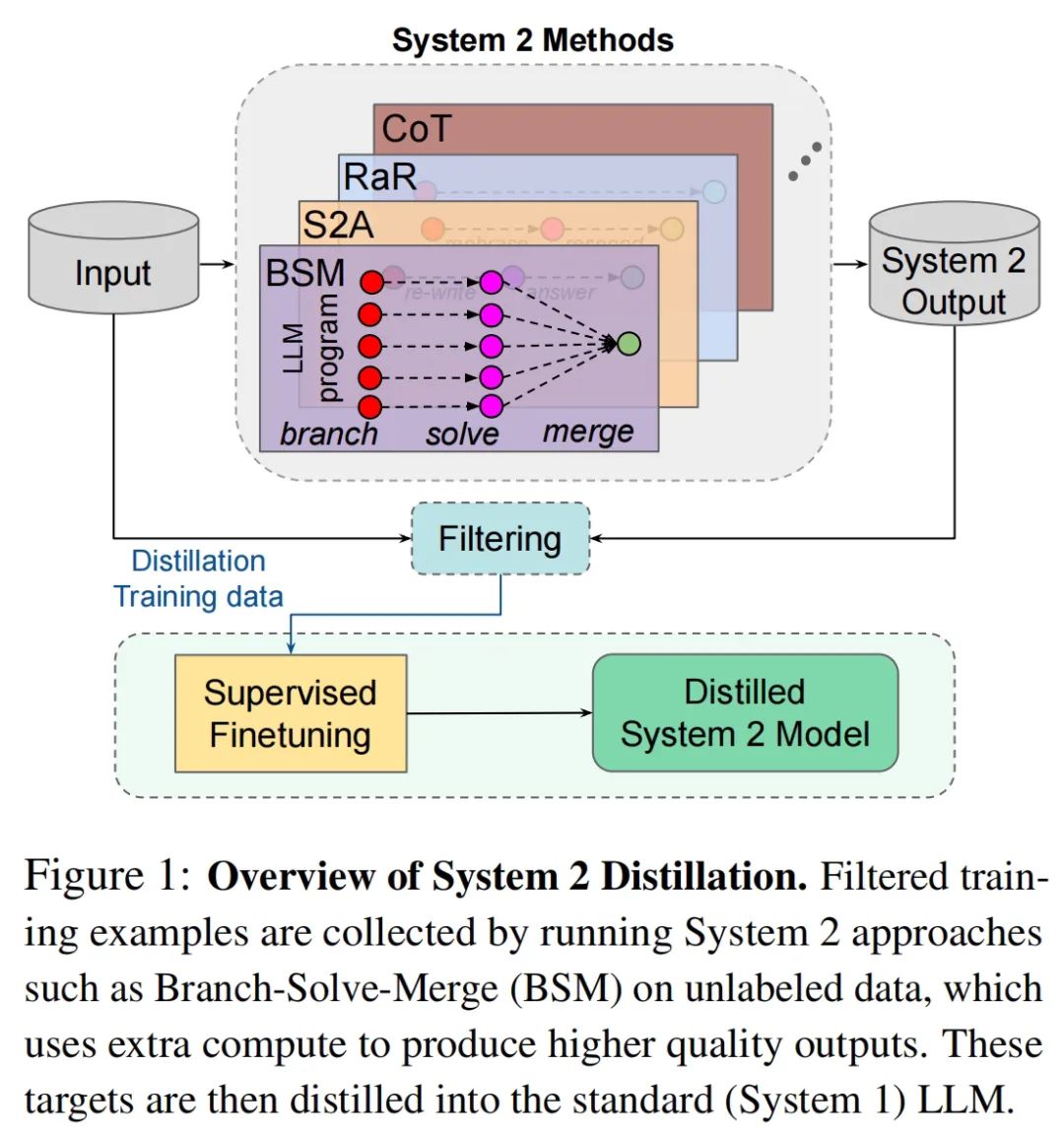
2-2. 清华类脑计算模型Dendristor登Nature子刊:受大脑启发的人工树突网络,比现有模型系统功耗更低
Dendristor 的突出之处在于它处理信息的方式与神经元及其网络的生物形态非常相似,而不是目前人工神经网络典型的批处理方式。Dendristor 模型实现了树突分支间和神经元间的特定塑性,从而提高稀疏神经网络中的学习效率。 这种方法允许 Dendristor 在其树突分支内对传入信号的序列和方向进行编码,从而提高其识别运动的能力。特别是模型中包含的「沉默突触」,即由树突分支电位激活的突触,增强了其对信号方向的敏感性,优化了其视觉感知过程。
实验结论:与现有的人工神经网络(ANN)相比,该系统展示了利用更少的神经元检测运动的潜力。
https://www.jiqizhixin.com/articles/2024-07-12-2
模拟树突形态的 Dendristor
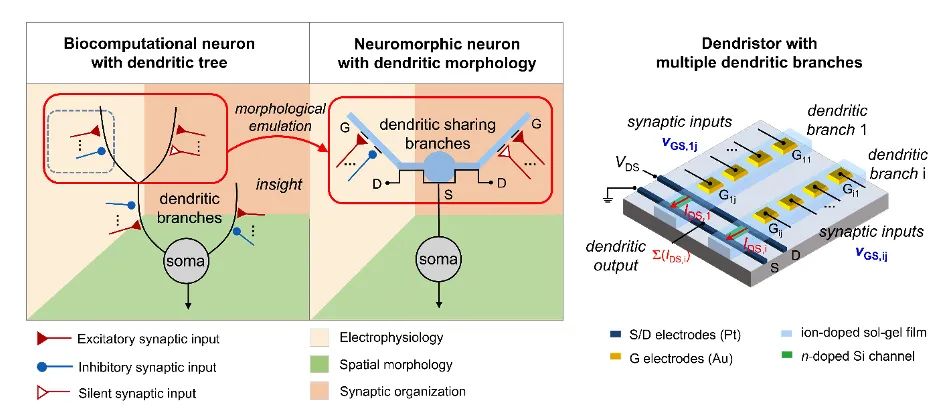
树突模型的方向选择性和沉默突触的效果
论文名称:Neuromorphic dendritic network computation with silent synapses for visual motion perception
论文地址:https://www.nature.com/articles/s41928-024-01171-7
2-3. LowMemoryBP大幅提升反向传播显存效率:在不增加计算量的情况下,显著减少峰值激活显存占用30%
文章提出了两种反向传播改进策略,分别是 Approximate Backpropagation(Approx-BP)和 Memory-Sharing Backpropagation(MS-BP)。Approx-BP 和 MS-BP 分别代表了两种提升反向传播中内存效率的方案,可以将其统称为 LowMemoryBP。 在实际实验中,LowMemoryBP 可以有效地使包括 ViT, LLaMA, RoBERTa, BERT, Swin 在内的 Transformer 模型微调峰值显存占用降低 20%~30%,并且不会带来训练吞吐量和测试精度的损失。
https://www.jiqizhixin.com/articles/2024-07-12-5

模型微调峰值显存占用降低 20%~30%
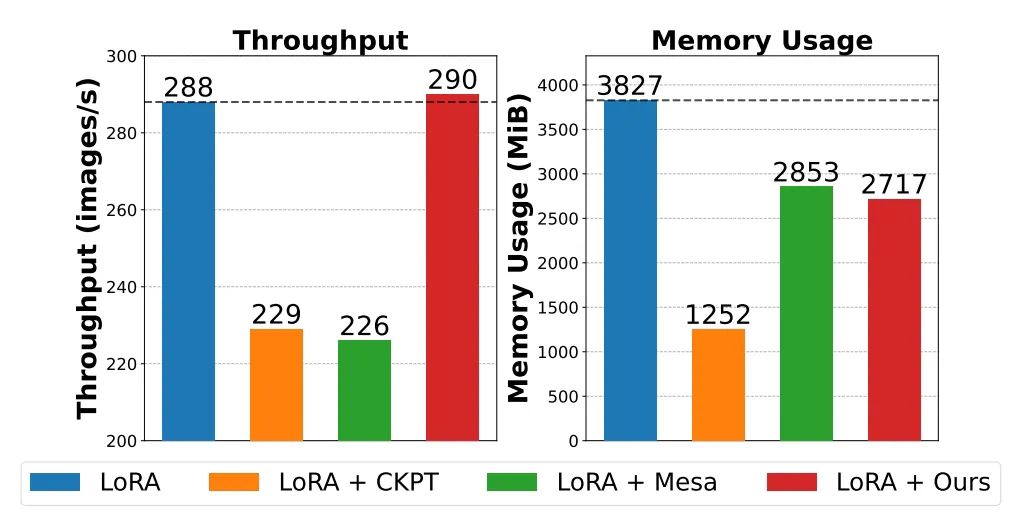
论文名称:Reducing Fine-Tuning Memory Overhead by Approximate and Memory-Sharing Backpropagation
论文地址:https://arxiv.org/abs/2406.16282
2-4. FlashAttention3来了:H100利用率飙升至75%,比之前提升一倍,比标准注意力模型快16倍
来自 Meta、英伟达、Together AI 等机构的研究者宣布推出 FlashAttention-3,它采用了加速 Hopper GPU 注意力的三种主要技术: 1. 通过 warp-specialization 重叠整体计算和数据移动;
2. 交错分块 matmul 和 softmax 运算;
3. 利用硬件支持 FP8 低精度的不连贯处理。FlashAttention-3 的速度是 FlashAttention-2 的 1.5-2.0 倍,高达 740 TFLOPS,即 H100 理论最大 FLOPS 利用率为 75%,而之前仅为 35%,使得 LLM 训练和运行速度比以前版本快
https://www.163.com/dy/article/J6T81PNB0511ABV6.html

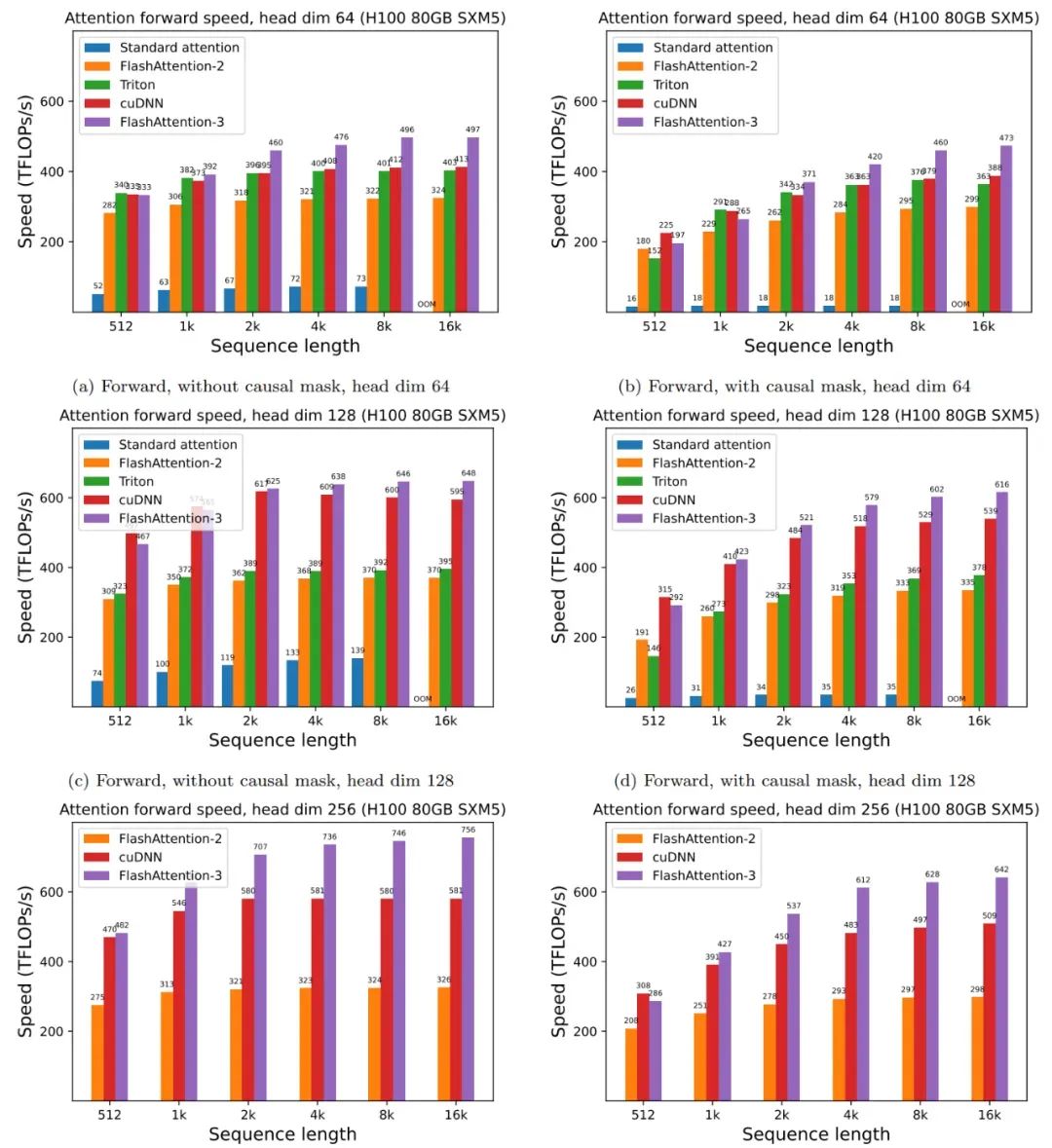
论文标题:FlashAttention-3:Fast and Accurate Attention with Asynchrony and Low-precision
论文地址:https://tridao.me/publications/flash3/flash3.pdf
2-5. 哈佛、UCSB等最新成果:低温采样技术助力生成式模型可超越训练集专家水平
生成式模型原本被设计来模仿人类的各种复杂行为,但人们普遍认为它们最多只能达到与其训练数据中的专家相当的水平。 不过,最新的研究突破了这一限制,表明在特定领域,如国际象棋,通过采用低温采样技术,这些模型能够超越它们所学习的那些专家,展现出更高的能力。
用通俗的话说,这篇论文的亮点在于展示了人工智能可以通过一种巧妙的方法——低温度采样——来集中大家的智慧,从而在特定任务上做得比任何一个训练它的专家都要好。这就像是把一堆专家的意见综合起来,通过“少数服从多数”的原则,得到一个更好的决策
https://www.163.com/dy/article/J6T822NQ0511ABV6.html

研究中用来展示模型在不同温度设置下的性能,并证明了通过低温度采样可以使模型达到超越训练它们的专家的能力
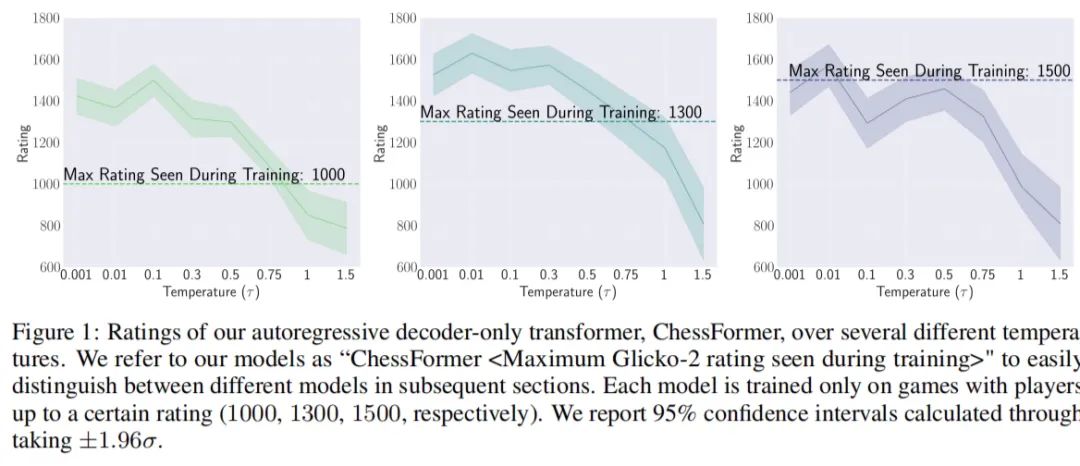
论文名称:Transcendence: Generative Models Can Outperform The Experts That Train Them
论文地址:https://arxiv.org/pdf/2406.11741
AI人才、融资动态
3-1. 红杉资本、英伟达等向人工智能初创公司Fireworks AI投资5200万美元
这笔投资对这家成立两年的公司估值为 5.52 亿美元。 据悉,Fireworks AI是一家为企业、开发者提供大模型微调、推理、部署等服务的平台。
与传统方法相比,Fireworks AI将推理时间减少了12倍,与GPT-4相比减少了40倍,每天处理1400亿tokens数据,API的正常运行时间达到了99.99%。
在过去的三个月中,Fireworks AI推出了 FireAttention V2,在长上下文提示的推理上快12倍,以及Firefunction-v2一个与 GPT-4o 相当的函数调用模型,效率提升2.5 倍,成本仅是其10%。
https://view.inews.qq.com/k/20240712A01A9500?no-redirect=1&web_channel=wap&openApp=false&sid_for_share=80217_3

3-2. 芯片巨头AMD:将以6.65亿美元(约合RMB 48亿)现金收购大模型公司Silo AI
AMD也表示,收购Silo AI是为了“基于开放标准,与全球AI生态系统紧密合作,提供端到端的AI解决方案”的又一步。 Silo AI在欧洲和北美均有业务,全球总部设在芬兰赫尔辛基,北美总部位于加拿大,专注于提供定制化AI模型和端到端的AI驱动解决方案,帮助客户快速将AI功能集成到他们的产品、服务和运营中。号称是欧洲最大的私营AI实验室,拥有300名AI科学家和工程师。
Silo AI还在AMD平台上创建了开源多语言大模型,如Poro和Viking,以及其SiloGen模型平台。
其客户包括安联、飞利浦、劳斯莱斯和联合利华等,据称迄今为止已经交付了200多个生产级AI项目。
https://www.qbitai.com/2024/07/165949.html