
在这个三维世界中,文字不再局限于纸面或屏幕,而是如水墨一般能够在空间中自由流动。想象一下,当我们用语言描述万物时,文字能够直接在空气中泼洒开来,如同魔法般展现出我们的想象。
最近,清华大学和哈佛大学的顶尖学者们联手开发了一项名为LangSplat的黑科技。这项技术利用三维高斯泼溅技术,让文字不仅仅停留在平面上,而是能够在真实的三维空间中“活”动起来。这种创新使得我们能够通过开放文本查询方式,直接在现实世界中获取信息和互动,为探索和学习带来了全新的可能性。
LangSplat是基于3DGS的先进3D语言场方法,利用SAM和CLIP技术,在开放词汇的3D对象定位和语义分割任务中表现优异,比当前最先进的LERF方法快199倍。
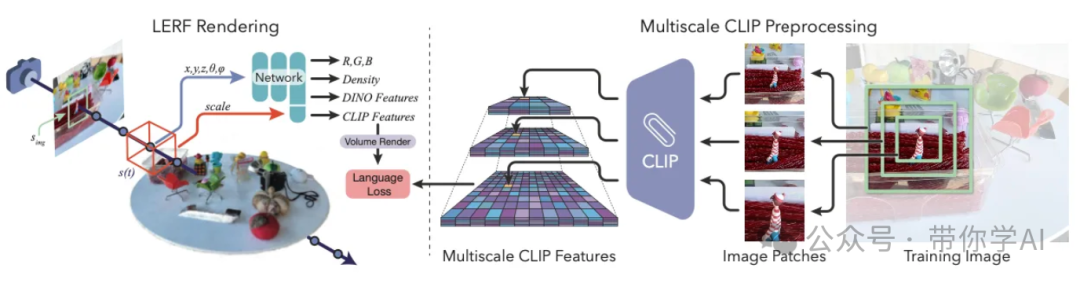
加州大学伯克利分校的研究人员在2023年3月展示了语言嵌入式辐射场(LERF)技术,将语言嵌入从现有模型(如CLIP)到NeRF中,使得能够在三维环境中准确识别物体,无需专门训练。
例如,你想在你家中迅速找到你可爱的小狗,只需要输入“小狗”即可。这项技术不仅适用于机器人技术和模拟机器人的视觉训练,还能增强人类与三维世界的互动能力。
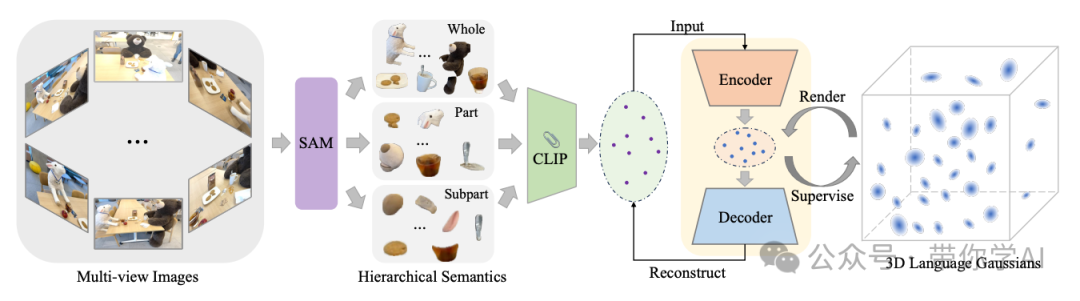
不过 LERF 的短板在于不适合实时搜索,且搜索结果准确率低。LangSplat 为了解决这个短板,使用 3D Gaussians 构建 3D 语言场,避免了 NeRFs 所需的复杂渲染过程,在 1440 x 1080 像素的分辨率下,LangSplat 比 LERF 快 199 倍。
LangSpla采用tile-based的三维高斯泼溅技术来渲染语义特征,从而避免了NeRF中计算成本高昂的渲染过程。首先训练特定场景下的语义自编码器,然后在场景特定的低维latent space上学习语义特征,而不是直接学习高维的CLIP语义特征,从而降低了计算量。
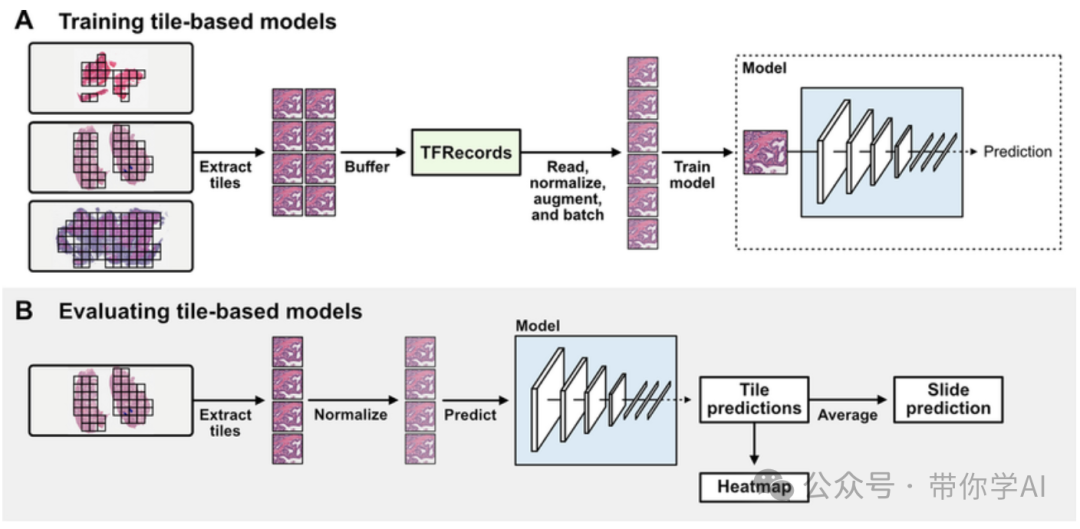
现有基于NeRF的方法的三维语义场比较模糊,无法清晰地区分目标的边界。LangSplat 为了形成 3D 语言场,使用 Meta 的“分段任意模型”(Segment Anything Model –之前的文章介绍过)从场景的多幅图像中学习分层语义。具体来说,图像会被分解成边界清晰的不同物体掩码,而物体又会被进一步分解成整体、部分和子部分。
LangSplat 利用 SAM 学习分层语义来解决点歧义问题。然后将片段掩码发送到 CLIP 图像编码器以提取相应的 CLIP 嵌入。使用这些获得的 CLIP 嵌入来学习自动编码器。
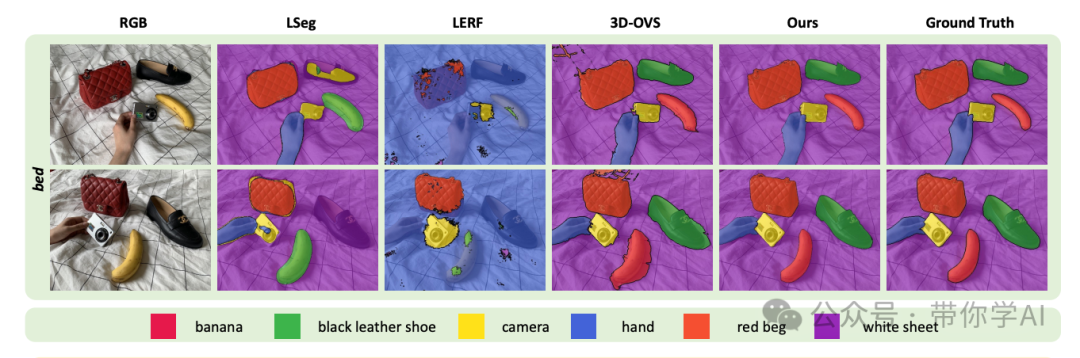
论文中展示了泡有茶叶的茶杯,LERF 标记的是两个杯子,而 LangSplat 标记的是杯子中的液体。在另一个例子中,它可以标记一碗拉面汤中的单个配料。






